

In 2018 at Developer, Developer, Developer in Sydney, my talk 5 Lessons for UX and ML was selected. It was a feat of extreme love for this subject matter, and a synthesis of everything I had learned at CSIRO’s Data61 at that point. I find the content still has relevance, as we still are not integrating the two practices very well in the wider industry.

So without further procrastination, let’s get started! Today I’m going to be teaching UX designers and Machine Learning Engineers 5 lessons on how to work with each other. It’s important stuff and often the emphasis is, I feel, on us learning each other’s skill sets when the key is to collaborate.

But just a warning that these are formed by my own experiences. Not from empirical data of any kind. These are lessons from the field, and I am still learning now how to best complete. Don’t be afraid though!

Also I would like to acknowledge that this talk was developed and delivered on lands of the Gadigal people of the Eora Nation. I would also like to pay respect to the elders, both past and present, acknowledging them as the traditional custodians of knowledge for this land.
Why make this talk?
So machine learning is at this interesting juncture where it has left academia and is being more widely seen in applied products. Both awesomely and also less awesomely, as there are now users and customers involved!

What could possibly go wrong, right?

And User Experience Design, in some form, has a long history of now being incorporated into commercial product practices to make these things usable. So therefore it should make sense that we’ll work together, right?

I’ve had a lot of lessons in the fact that often when I’ve walked into a room, there’s been a lot of engineers discussing things that I don’t understand, such as k means.

If I did ask for, example, what this meant. The engineer would, with kind intentions, link me a large wikipedia article on it.

I would then follow up with a low lying questions such as “what is clustering”

And then there’d be this follow up situation where they’re not quite sure what I know and I don’t really understand them so I’m just trying to ask them everything and they’re not quite ready to give a crash course in machine learning.
So let’s just start from the basics of where we both stand:

Here’s a User Experience Designer. Maybe they’ve started with a qualification from a vocational college (in this case, General Assembly or, in Australia, what’s called a TAFE school). Or maybe they’ve got a Bachelor’s, a Masters, or a PhD in Human Factor Design or Psychology. They might have had a commercially focussed or academic education.
The net and potential variation is wide! Mostly, they come into commercial practice highly prepared because success in their school looked like understanding and designing for “wicked” problems that might’ve never had a design process before and creating amazing novel solutions. This was accompanied with direct feedback from their course’s commercial partners and validation as part of their education.
Commercial work might’ve then entailed working on different briefs, maybe not always following what we call a full design process and very geared to business driven outcomes that are determined by how much a client is willing to pay or what a business is willing to allocated.
Success can now largely be determined by user growth or potentially how satisfied the customers are with ongoing work. So when they get the chance to work with something new they’re naturally very excited! It’s AI! It’s the FUTURE!

Machine Learning Engineers, that I have worked with, tend to have a lot more education in a field that is still somewhat novel and new. Furthermore, they’re often the most knowledgable people in the room and what they’re experts in is not Design adjacent. For example advanced mathematics, physics or computer science.
Also they have been educated in a way where success is quite different. It focuses on novel mathematics or novel implementations and success can be publishing a paper that other Machine Learning academics are interested in.
However, commercial level work often limits experimentation to what code can be made production ready. There are also business goals that maybe don’t favour creativity and there are actual users of the products, which brings in a new world of complexity.
So some Machine Learning engineers I have known can grow quite bored in commercial roles and organisations as it can become about refining an algorithm and measuring the uptake by user numbers.

Designers can often feel like they’re behind the engineer, and can be a bit nervous because they lack this kind of deep technical knowledge.

Machine Learning Engineers are often not versed in potential impacts of their work, or as a colleague put it, not realise that granny might one day use their search algorithm.

But here’s an example my former colleague, Hilary Cinis, worked on that I’m going to talk through. This was about Air Quality Measuring where they were making today vs. tomorrow predictions about air quality with a lot of research going into the model in terms of machine learning.

But let’s take a back step for a moment….
I’m defining Artificial Intelligence as the larger definition, where machines mimic human intelligence fully. This is in contrast to what Machine Learning does where, much like a human toddler does, it learns from previous example but this what’s known as a narrow form of AI. It creates a model that can take in data, of a certain type, and create predictions. Often in the form of question and answer. Here’s the special thing though, models can be used on data that it was not trained with, to make predictions. However, this is provided it’s the same type, you don’t ask a model to find the dog in the picture if you trained it on cats.
Let’s go back to our example.

In our Air Quality Measuring problem, the industry application had several UI issues but also its model could not always be relied upon for what it was required to do. Thus it could have been a great and interesting academic paper, but not a industrial success.

So how do we get the best of both worlds? Both an academic novelty, and a fully reliable industrial application? In 2021, I think we’re inching forever closer to this, but still not completely there yet. But I can teach you the 5 Lessons to get closer to this and what has worked for me so far.

So here are my 5 lessons:
- How we make ux work for everyone
- What machine learning engineers REALLY need to tell designers
- How to get engineers testing with users too
- How we can sketch together
- Briefly I’m going to touch on ethics too
Lesson 1 – Establish Mutual Benefits of UX Process


So here are the benefits of the ux process but first, maybe counter intuitively, we will talk about what the engineers get out of collaborating with UX.

So a dear friend of mine was working on a project where she was using a lot of people’s personal information. After consulting with a few people, including other engineers and the lead of the project, she had a clear idea of what algorithm she was going to use. But the trouble was that she wasn’t given the opportunity to talk with the designer and thus these two parts of the project were done separately. In the end, she felt that the two halves of the product were therefore highly disconnected, and hence doesn’t know if what has been implemented has been used well.

So how do we both work? It is a source of eternal shame to me that I thought, in the beginning, that everyone had to know how important the UX process was and what it could do well. This is not true, a lot of machine learning engineers haven’t worked with UX before and don’t really understand what we do and what’s involved. Basically, this assumption wasted a lot of valuable time and I didn’t check in when I should have. It also didn’t give them an opportunity to check in with me. When I did I discovered that we actually work more similarly than maybe a front end developer and UX person does.

Here is the typical UX process, a fusion of my own practice and maybe what IDEO Design Thinking looks like. Basically, we pitch to clients, figure out whether UX is going to solve their issues or not and therefore what follows are a lot of scoping exercises to manage expectations. Then we get into the “real design” part, whereby we research a lot about our users, think about potential solutions and then test whether it’s suitable. We do this as many times as needed or before we really have to give it off to development. Sometimes this has variations, maybe if you’re sure what elements you will be using, your development team might get started early on the designs but it largely depends on the team and the appetite for process.

Coincidentally – This is how Machine Learners work (according to people I have worked with). They also work out whether machine learning is actually needed and or possible on projects, because, spoiler alert, the client often isn’t ready for their involvement. A machine learning group can probably then spend 80% of their time cleaning up data. It’s not unknown for data to be sent in PDF form. They then also enter this loop of experimenting with different approaches, different algorithms, maybe trying different parameters to get different predictions. Their delivery can either be a report or model.
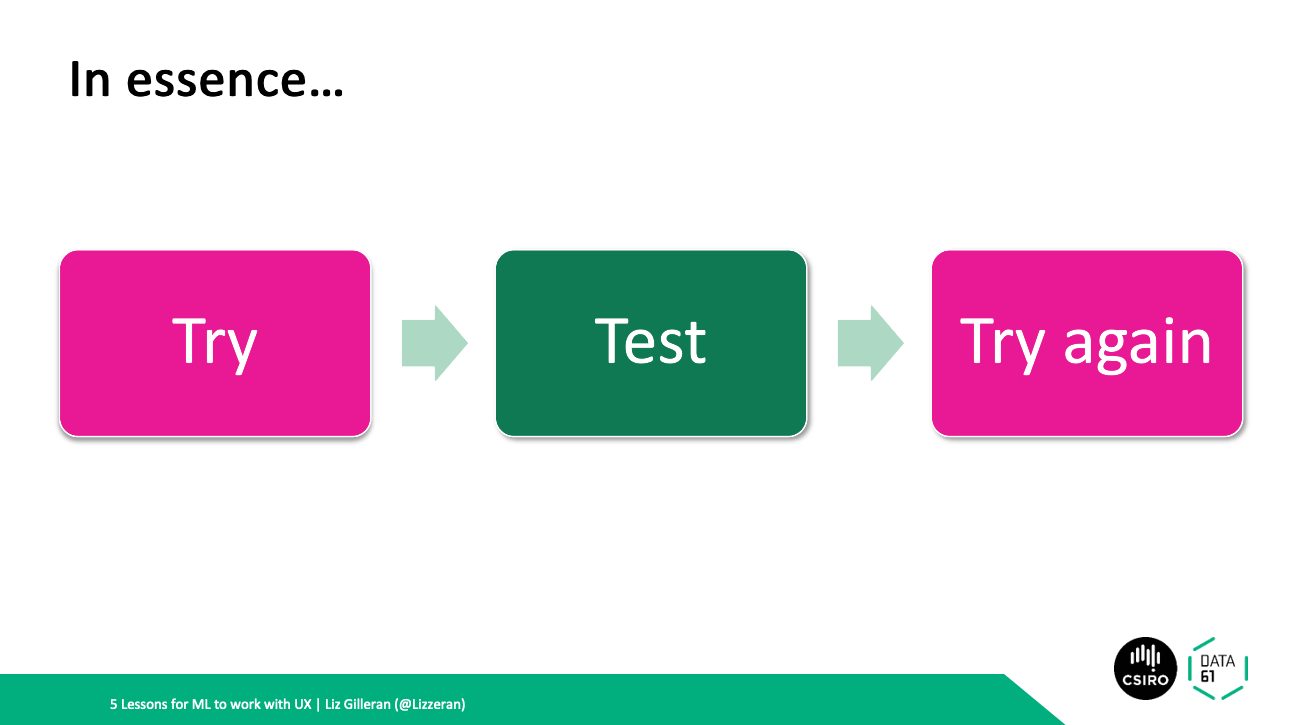
But basically we’re both in the business of try test then try again! However you might like to put it.

So what do we need to benefit from UX ? UX Designers really need to communicate to the Machine Learning Engineers what the goals of their work really is, what activities they’re doing and why they’re doing them. Then talk about the users and why this person is the user and then talk about the assumptions they may be making about the data/feature selection. The UX designer really needs to put their cards on the table as to how they see their work benefiting the Machine Learning process and discuss it very openly. Assumptions are never good.
The ML Engineers also have their own responsibilities! They need to be actively discussing the limitations of the technology, nip wild product feature ideas in the bud before an AI optimist pitches them to someone in the business! Be gentle, UX designers as we’ve discussed, often don’t have technical expertise. Explanations may have to be very basic in some cases depending on the person but don’t be condescending. You can suggest better ways of working or how better data collection could occur, particularly if they’re doing something unethical.

I know first hand how to fail at this and I did so very early on in my career, before the Artificial Intelligence hype. It was on an early stage alpha prototype for data ingestion, where a user could come through, select an algorithm and features etc. The trouble was the UI didn’t articulate the relationship of the data to the end result and I was too scared of feeling foolish in front of two PhDs who bantered around terms like Random Forest easily to really press on articulating how to demonstrate that relationship.
Summary Lesson 1
- Figure out the mutual benefits (usually: better UX = better data collected = better models = more use!!)
- Encourage both the UX Designer and ML engineer to communicate what they’re going to do and why they’re going to do it
- Find a common interest and a common goal
Lesson 2 – Communicating Complexity to Designers

So let’s start with figuring out where UX designers are coming from in this situation. Basically, they ask a lot of questions. It’s encouraged early on in their education to do things like ask “why” 5 times
What UX Designers tend to do
- Ask a lot of questions
- Be very annoying with those questions
- Have the best intentions

Most people, once they grasp what ML can do, like a hammer, all data looks like a nail. Misguided but optimistic!

This brings us to “what do they actually need to know?” And here’s a checklist that I’ve got so far.
An Example – Voice Recognition

A a voice recognition system. It’s an exciting new technology in alpha stage that detects mispronunciations. Great! Potentially a clear product direction. The data is coming from a study, the machine learning, as is often what happens in voice recognition is an unsupervised learning technique. It’s also not likely that our users will understand how this all works or how the results are derived.

Let’s just back up for a second and look at what this might all mean code wise. Machine learning never made sense to me, personally, until I saw this example of how the code is structured, side by side. So, programming, how we think of it, might all just be a collection of conditions, if this then that. Simple? But machine code often looks more like the above: given some samples, try to reduce errors, repeat. Which is how you end up with folklore like this which could possibly or not possibly be true.

Some users think the mistake is them and is reflective of biases they might have previously encountered. Such as in this example, I did not have the algorithm working, it was a user interface tool that I think might’ve been going slowly. But it was a dummy test and the user was given a fail result randomly and they said oh maybe it’s picked up my accent and that’s why it won’t work. There’s also the alternative, if the limitations of the technology aren’t communicated well there’s well deserved scepticism too, such as saying a model has 92% accuracy. What does that mean for someone who is using it?

This might sound simple and a bug of new systems, but if they’re not taken seriously, there’s no trust and therefore no cool tech and therefore no one benefits.

So let’s think back… what are the limitations of the technique we’re using (unsupervised), what are the limitations of the training data, and what are the ways that a user can make a mistake with the output also are we confident in communicating the data?
In short, we’re using a machine learning technique where the machine decides it’s own categorisation so debugging would be really difficult. Also, the data we’ve got from the study might not be very diverse at all and not appropriate to deploy. The algorithm could end up very specific to one small group and hence the users can make mistakes with the output by thinking it’s their fault. So our saying that the algorithm is 92% accurate makes them feel potentially excluded.
Summary of Lesson Two
- Figure out where your models/methods could cause problems
- Figure out how to best explain what is happening to the data within reason
- Test that they (the users) actually understand
Lesson 3 – Involve the Engineers in User Testing

How to Involve Engineers in User Testing and Research
- The importance of user testing and research
- A story of a very involved engineer
- How to involve the engineers/How engineers can ask to be involved

Do you remember this part of the UX testing? That at the beginning and end of the process there tends to be problem definition and testing.
Why it could be important with ML
- Get feedback before deployment to a larger user base
- Test whether the user case you were aiming for exists
- Sometimes it’s also a good time to see if what data you think is relevant to the end user actually is


One ML engineer colleague once came to 20 user interviews, and this has remained my gold standard. But the trick is so that the engineers also understand how the interface is being used and interpreted by real people. Participation in user testing is often more effective than reading dot points on a report.

Summary of Lesson 3
- Let the engineers come along and ask the users their own questions
- Foster discussions afterwards and team up if you need to change the project leader’s mind
Lesson 4 – Sketching Solutions

So first up- let’s talk about the benefits of sketching

Sketching prevents the merry go round of designing something showing it to a tech team then correcting it then going off into the designer bubble to produce another idea showing it and trying again.
Instead, though sketching together, encouraging a sketch with the whole team, reflecting on the product design as a whole, refining the concept, testing it with colleagues and then going in for a final design. Visualisaing information is important. We know that data visualisation creates a “knowledge crystallisation” effect and I believe the same is true about sketching (Card, M. (1999). Readings in information visualization: using vision to think. Morgan Kaufmann). There’s nothing as powerful as showing what you mean, words only go so far.

Hence: sketch workshops. Usually done for for co designing interfaces in what I like to think are fairly obvious kind of projects where there might not have been technological intervention before. But it can be done for systemic processes as well. It’s a usual step of what’s called the SPRINT method by Google Ventures. The Ventures sprint is usually done over a 5 day period of co creation exercises in order to get a product into production and test. It’s quite good really and follows a structure of many ideas followed by a longer solution sketch.
See: https://designsprintkit.withgoogle.com/methodology/phase3-sketch

However, this can have several pitfalls when dealing with a less straightforward problem:
- Value propositions aren’t usually immediately clear with ML
- This is asking engineers to get into a “new language”
- Often ML practitioners are more comfortable with mathematical symbols

Here’s a mnemonic I created as, with one team, I bribed them with cake to get into my workshops. But hey it works! Capture Attention Keep Iterating. See here’s the rules: generally the UX designer sets the agenda, they need to get certain things out of the workshop and you need to let them.
- Everyone else needs to relax, think less and foster collaboration not control. It’s a fact finding exercise for your input into what the project.
- Listen to the direction but also the Designer really needs to set a finite time on certain tasks (90 minutes should be the peak with a break, possible for cake, in between).
- As you can see, I do a warmup sketch for 10 minutes, maybe something silly like drawing a person with an idea and comparing ideas, followed by reviewing an older interface and deciding what really needs to be fixed and has so many ideas surrounding how it could be fixed. Followed by a solution sketch for 20 mins and a 30 minute critique. Time can fly!
- Critique is the most important part, and it might generate plenty of How Might We’s (https://designsprintkit.withgoogle.com/methodology/phase1-understand/hmw-sharing-and-affinity-mapping) about the ML work going on if something has changed in the interface. This is good! e.g. How Might We handle many different accents in Voice Recognition.
Example Agenda
- Warm up (10 mins)
- Review previous work (10 mins)
- Decide on Sketch problem (20 mins)
- Critique (30 mins)
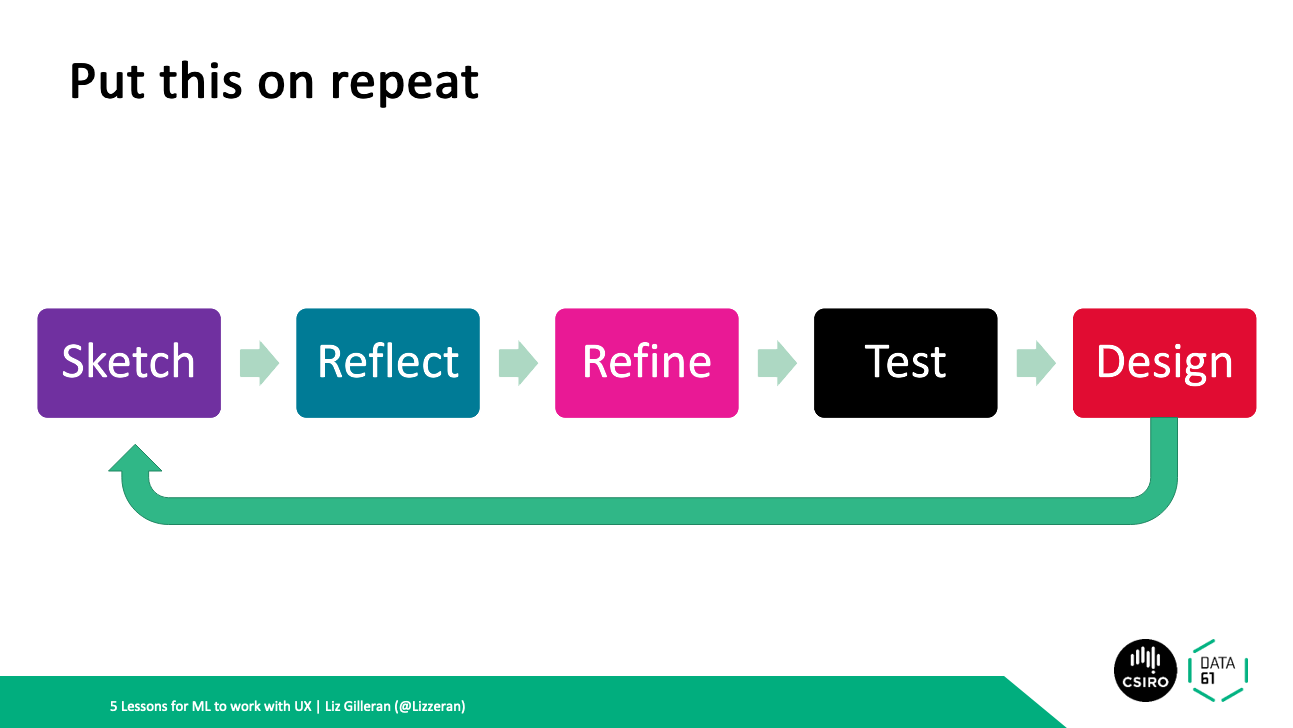
So the process will evolve, there’ll be sketch reflect refine test design and then back to sketch again. It’s unlikely you’ll get it right the first time.
Signs of a Good Workshop
- Participants are laughing and having fun (within reason!!!)
- The engineers might actually go have a re-think about how the whole thing works
- They’re asking to come back and do this again
- Flow diagram sketches are completely fine
- Someone has pointed out an intricacy to whatever tech you’re working with that meant success or failure
Signs of it going awry…
- Participants continuously on phones or email
- Someone is trying to divert the workshop control away from the Designer without permission
- Running over time continuously
- Find what will work the best for your team
But remember CAKE: Capture Attention Keep Experimenting
Summary of Lesson 4
- Visualise information to discuss important aspects
- Find what works for your team
- Capture everyone’s attention and keep experimenting (CAKE)
Lesson 5

This is a bit of a weird lesson
- Some ethical problems are seemingly obvious in retrospect
- I have the benefit of an ethics committee at the CSIRO which isn’t available to everyone
- This is all about starting the conversation
- There is SO MUCH literature in this topic now that I cannot possibly cover here, but I encourage you to go and read as much as possible.

Take this Scenario
- You’re young and very intelligent (lucky you!)
- You come up with an AWESOME idea for an algorithm
- It has academic background backing
- Someone wants to fund what you’re doing with real world users and data
- What could possibly go wrong?

If you’re in a team
- Encourage your juniors to ask questions about ethics
- Encourage personal experience sharing
- Allow open conversations and questions about the technology
Especially…
- Data Provenance
- Treating the data with respect
- Potential future data use
- Expect non favourable results
An example of harmful results
One concept that we might be able to glean from accessibility is the principle of designing for, what Microsoft Design calls the persona spectrum (See: https://www.microsoft.com/design/inclusive/ ). Imagine if we had a Social Media feature that revived old photographs, maybe that had been interacted with heavily in the past, and reminded you of those moments. Let’s imagine how that might go down in how badly it could go:

For those who don’t think this could happen, it did happen. It was Facebook’s Year in Review Feature and it very personally effected Eric Meyer (Content warning: discusses a child’s death, https://meyerweb.com/eric/thoughts/2014/12/24/inadvertent-algorithmic-cruelty/ ). Even Google’s Human Centred AI team recommends planning for how the system works to weigh up whether the results are worth the unkindness it may inflict (See: https://medium.com/google-design/human-centered-machine-learning-a770d10562cd)
In Summary, the lessons:
- Establish the mutual benefits of the UX Process
- Communicate the ML complexity to Designers
- Involve the Engineers in User Testing and Research as much as possible
- Sketch Solutions Together
- Make Ethics Everyone’s Responsibility
Special Acknowledgements
- Hilary Cinis
- Simon O’Callaghan and Alistair Reid
- Renee Noble
- Louis Tiao
- Rosie Prom
- Tea Christodoulou
- N1 Analytics (Max, Jakub, Wilko, Hamish, Guillaume, Brian and Giorgio)
- Kristina Johnson and Sara Falamaki

- Also thank you for your votes for this talk and the DDD sponsors
References and Further Reading
- Ben Crother’s Presto Sketching
- Hilary Cinis’ writing on Ethical Technology http://hilarycinis.com/ethical-technology-crafting-part-1-purpose-and-position/
- Look Up: Human in the Loop Machine Learning, Human Centred Machine Learning (particularly anything by Saleema Amershi)
- Google’s UX + AI library https://design.google/library/ai/
- Sara Wachter-Boettcher’s 2017 Book Technically Wrong is a good place to start
- Jason Meyer’s Slide Deck “Machine Learning 101” https://docs.google.com/presentation/d/1kSuQyW5DTnkVaZEjGYCkfOxvzCqGEFzWBy4e9Uedd9k/preview?imm_mid=0f9b7e&cmp=em-data-na-na-newsltr_20171213&slide=id.g168a3288f7_0_58 (I’ll tweet this…)
- All photos unless stated otherwise are from Pixabay or Unsplash under a CC0 license